DDPM论文浅析
论文链接:Denoising Diffusion Probabilistic Models
这篇论文的贡献主要有两个
- 证明扩散模型确实有能力生成高质量样本
- 证明扩散模型的一种特定参数化方法与降噪分数匹配(denoising score matching)等价
一些主要前置知识:
变分推理(Variational Inference)
扩散模型:Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Score Matching:Estimation of Non-Normalized Statistical Models by Score Matching
Score-based Generative Model:Generative Modeling by Estimating Gradients of the Data Distribution
另一篇非常好的参考博客:https://aman.ai/primers/ai/diffusion-models/
Diffusion Model
设$\mathbf{x}{0}
设
该马尔可夫链定义为根据方差表
前向过程的一个重要性质是可以解析地在任意timestep进行对
证明:
使用重参数化(reparameterize)技巧,设
采样得到隐变量序列后,可以得到后验
现在再定义另一个逆向马尔可夫链,其初始分布为
进一步可得联合分布$p{\theta}\left(\mathbf{x}{0: T}\right)$
扩散模型(Diffusion Models, DM)的思路是用$p{\theta}(\mathbf x{t-1}|\mathbf xt)
通俗的说,DM对样本不断加噪直到几乎只有高斯噪声,然后再学习加噪的逆过程,即从高斯噪声不断降噪直到获得一个样本

$p{\theta}(\mathbf{x}{0})$的训练是通过优化变分下界进行的,即
直接计算这个式子需要MCMC采样,方差会比较大,因此将
证明:
改写后的
$L{t-1}
正态分布间的KL散度是可以直接计算的,这样就避免了MCMC
Score-based Model
Score Matching最初的目的是计算非归一化概率模型的归一化常量
其论文中将Score Function定义为对数概率密度的梯度(the gradient of the log-density)
Score-based Model的目标是训练是一个分数网络
由于数据的Score Function是未知的,该式需要进一步推导,可以证明,该式在常数差距内等价于
此时$\operatorname{tr}(\nabla{\mathbf{x}}\mathbf{s}{\theta}(\mathbf{x}))$仍是难以计算的,不同的Score-based Model目标就是解决这个问题
一种比较常用的方法是降噪分数匹配(denoising score matching)
其首先使用一个噪声分布
可以证明该式最小化时有$\mathbf{s}^*{\boldsymbol{\theta}}(\tilde{\mathbf{x}})=\nabla{\mathbf{x}} \log q{\sigma}(\mathbf{x})
获得了分数网络$\mathbf s{\theta}(\mathbf x)$后,我们可以使用Lagevin Dynamics(或称Lagevin Sampling)从Score Function $\nabla{\mathbf x} p_{\mathrm{data}}(\mathbf{x})$中进行采样,它是一种MCMC采样方法
给定固定步长
其中$\mathbf{z}t\sim \mathcal N(0, I)
Diffusion Models and Denoising Autoencoders
通过指定不同的$\betat
下面要讨论的一种实现将使扩散模型产生与降噪分数匹配等价的效果
对于
对于逆向过程 $p{\theta}\left(\mathbf{x}{t-1}|\mathbf{x}{t}\right):=\mathcal{N}\left(\mathbf{x}{t-1} ; \boldsymbol{\mu}{\theta}\left(\mathbf{x}{t}, t\right), \boldsymbol{\Sigma}{\theta}\left(\mathbf{x}{t}, t\right)\right)$
首先,令$\boldsymbol{\Sigma}{\theta}\left(\mathbf{x}{t}, t\right)=\sigma_t^2 \mathbf I
从实验结果来看,$\sigma^2t=\beta_t
The first choice is optimal for
, and the second is optimal for deterministically set to one point. These are the two extreme choices corresponding to upper and lower bounds on reverse process entropy for data with coordinatewise unit variance.
此时我们可以根据正态分布间的KL散度公式进一步推导得
其中
前面提到前向过程可以在任意时间步采样,即
我们对其使用重参数化技巧,令
从这个推导结果容易得到,对于均值
其中$\mathbf xt
确定均值的参数化方法后,
此时可以明显看出该式与降噪分数匹配非常类似,实际上是在多个尺度的噪声下进行降噪分数匹配,其中的
下面给出该参数化方法下扩散模型的算法伪码,如Algorithm2所示,采样$\mathbf x{t-1}\sim p{\theta}(\mathbf x{t-1}|\mathbf x_t)

Discrete Decoder of Reverse Process
由RGB表示的图像中每个像素点离散地在
为了获得离散似然,我们需要将逆过程的最后一步改写为一个独立的离散解码器(independent discrete decoder)
以下我们假设所有图像的像素值都从
由于上述推导中假定逆过程的协方差矩阵是对角阵,所以显然有
其中
接下来使用分箱进行离散化,即像素点取值在区间
Simplified training object
作者在实验中发现,将前面推导的得到的训练目标进一步化简可以得到更好的生成效果
其中
Experiment
IS和FID是评价(图像)生成模型的常用量化方法
IS(Inception Score)使用Inception Net输出图像
清晰度:对单一的生成图像,其类别分布的熵应尽可能小,即对于清晰的图片,其属于某一个类别的概率应趋近于1,其余则趋近于0。因此最小化
多样性:对成批的生成图像,其类别分布的熵应尽量大,即生成模型生成的图像类别因尽可能丰富,因此最大化
将前者取负,两者相加后得IS表达式,IS越大,生成图像质量越高
FID(Frechet Inception Distance)使用Inception Net-V3并删除最后的分类层,得到图像的2048维特征向量
FID的思想是直接计算真实图像分布和生成图像分布的距离,但图像分布维度过大不易计算,因此使用Inception输出的2048维特征向量计算Frechet Distance,显然FID越小越好
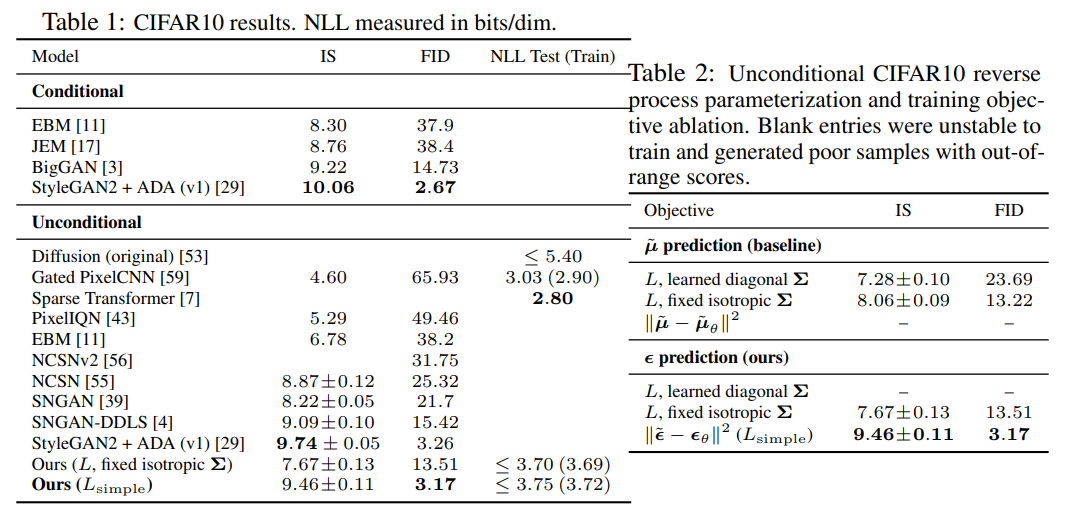
下图Table 1、Table2展示了DDPM的IS、FID和NLL比较
由Tabel 1可知DPPM的IS仅次于StyleGAN2+ADA,而FID则最优,对于负对数似然NLL,论文称使用未化简的变分目标得到的NLL更好,但图片质量不如化简的目标
Table 2对比的是不同的